Google のクローラー / フェッチャーの一種である Googlebot は、各サイトを巡回するさいに「HTML の最初(冒頭)から 2MB まで取得する」仕様になっています。
仮に HTML が 10MB だった場合、1/5 程度しか読んでくれないわけです。
しかし、HTML が 2MB を超えるのはかなりのレアケースで、通常は気にする必要はありません。
HTML サイズの確認方法や、レアケースに該当するサイトについて解説していきます。
HTML サイズの確認方法
まずは自分のサイトの HTML サイズを調べておきましょう。
HTML サイズチェッカー(セオツールズ)
当サイト(セオリコ)で開発した「HTML チェッカー」は、サイトの HTML サイズを無料で計測できます。
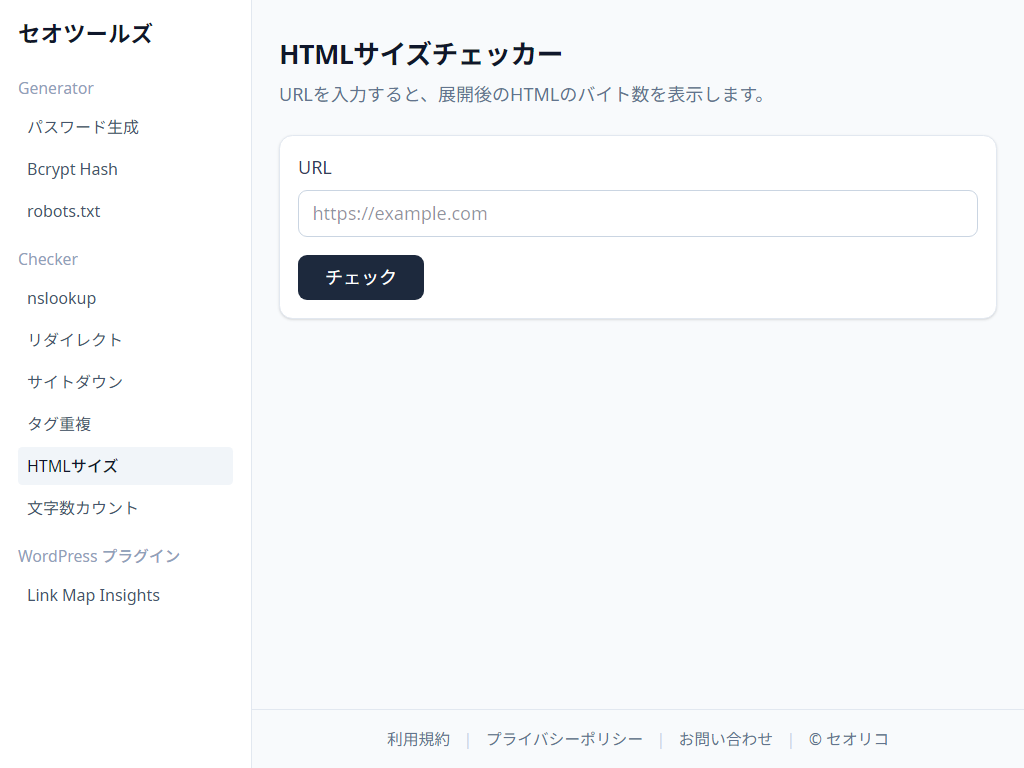
サイト内の全ページを一括チェックするツールではありませんが、長文記事など「これはサイズが大きそう」というページをチェックするだけで十分です。
とくに WordPress であれば <head> 内などの共通パーツはどのページでもほぼ同じコードを出力しますから、差異はメインコンテンツである記事本文部分となります。
Ahrefs Site Audit
サイト全体の監査が必要であれば、Ahrefs をおすすめします。
2MB を超えるページを自動検知して通知してくれます。
🆕 重要!サイト監査が「2MB」を超えるページを自動検知!
— Ahrefs Japan 公式 (@AhrefsJP) April 1, 2026
Googleが最近ドキュメントを更新し、「Googlebotは非圧縮HTMLの最初の2MBのみをクロール」 と明記しました。
【影響】
2MB以降に配置された:
❌ 重要なテキスト
❌ 内部リンク
❌ 構造化データ
→ Googleに認識されていない可能性… pic.twitter.com/GitJ1Be6VI
※ 2026 年 4 月時点で、無料版では確認できませんでした。のちのち使えるようになるかも。
手動で確認する
ツールを使わず、手動によるチェックもできます。
チェックしたいページを開き、右クリックで「ページのソースを表示」してください。
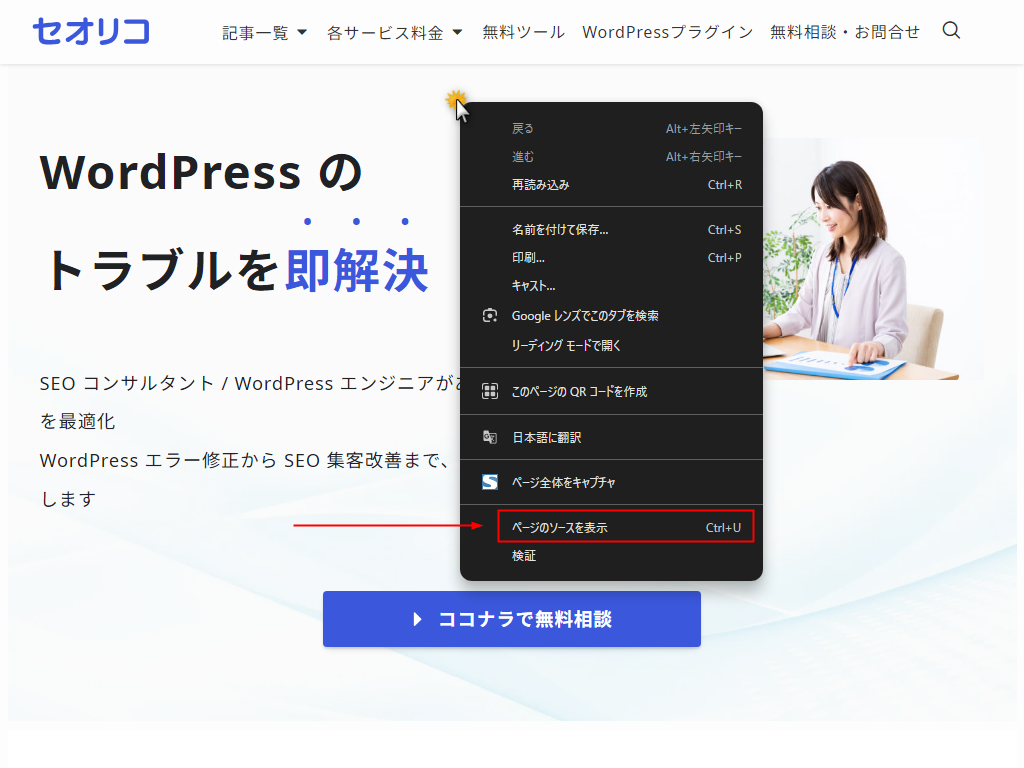
HTML コードが表示されるので、Ctrl + A で全選択してコピーします。
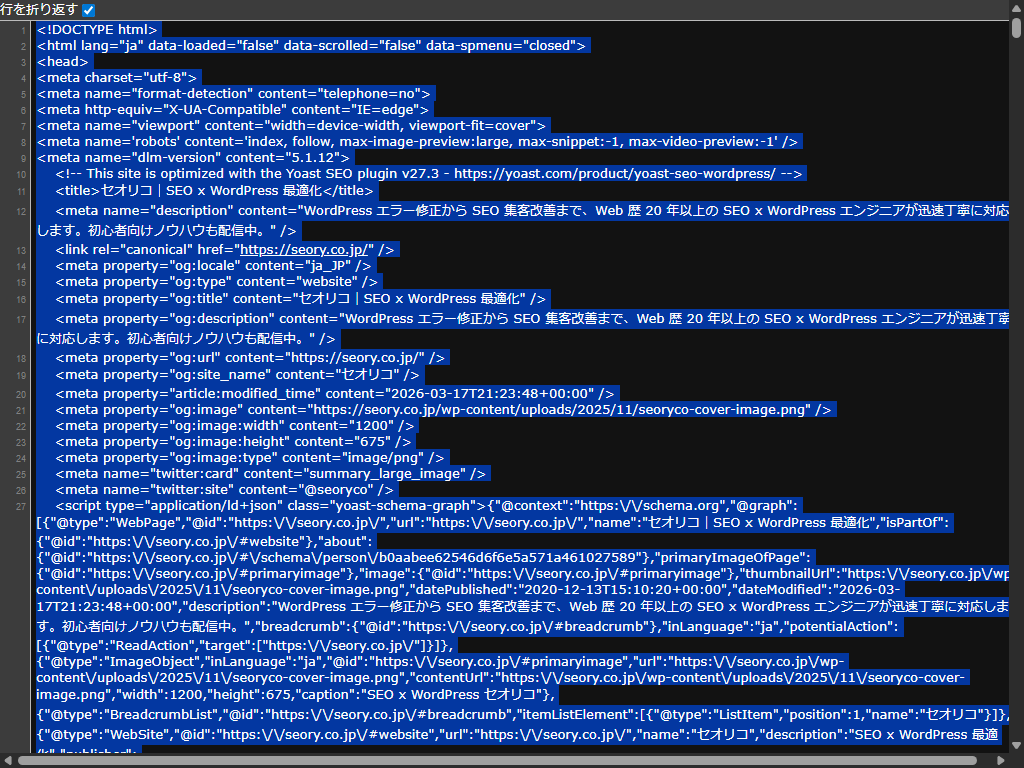
テキストエディタに貼り付け、sample.html など適当な名前で保存。
保存したファイルを右クリックして「プロパティ」を開けば、サイズを確認できます。
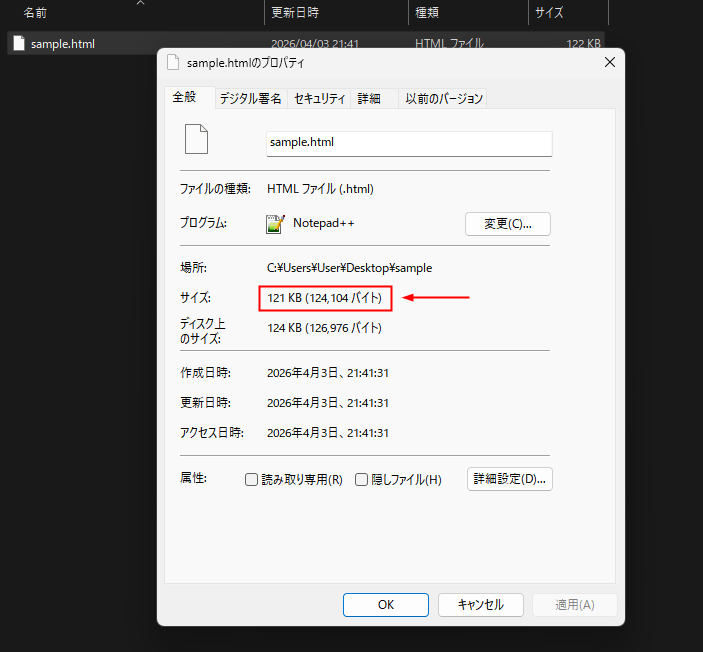
実際に Googlebot が読み取るサイズと数 KB の誤差があると思いますが、だいたいのサイズを知りたい場合はこれで十分です。
Googlebot の 2MB 制限とは
Googlebot は、Google 検索用のクローラー / フェッチャーです。全世界の Web サイトをクロールし、ページ情報を取得しています。
- クローラー
-
Web サイトをクロール(巡回)します。
- フェッチャー
-
Web サイトの情報をフェッチ(取得)します。
このほかにも広告や AI など複数のクローラー / フェッチャーがあり、それぞれ制限が異なります。
Google のクローラーとフェッチャーは、デフォルトでは、ファイルの最初の 15 MB のみをクロールし、この制限を超えるコンテンツは無視されます。ただし、個々のプロジェクトでは、クローラーとフェッチャー、およびさまざまなファイル形式に対して異なる上限を設定できます。たとえば、Googlebot のような Google クローラーに対して、サイズの上限を小さく(2 MB など)したり、HTML よりも PDF のファイルサイズの上限を大きくしたりすることができます。
Google クローラー(ユーザー エージェント)の概要 | Google クロール インフラストラクチャ | Crawling infrastructure | Google for Developers
2MB 制限は HTML 単体の話であり、画像などすべてを含めた 1 ページのサイズではありません。
HTML や CSS、JS などはそれぞれ個別に 2MB まで読んでくれます。
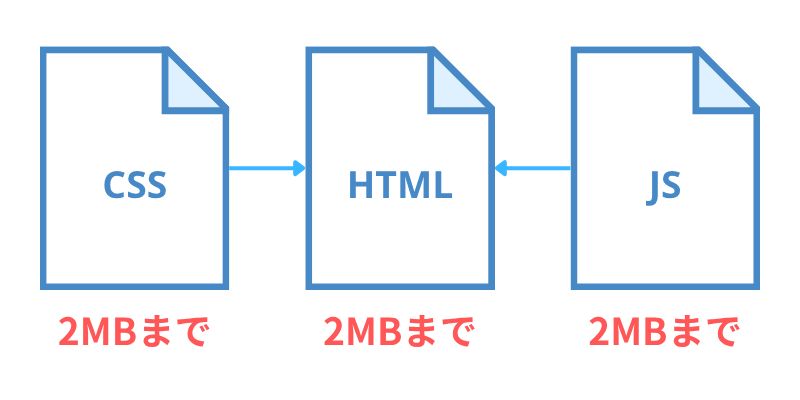
Google 検索のクロールでは、Googlebot はサポートされているファイル形式の最初の 2 MB と、PDF ファイルの最初の 64 MB をクロールします。レンダリングの観点から見ると、HTML で参照される各リソース(CSS、JavaScript など)は個別に取得され、各リソースの取得には、他のファイル(PDF ファイルを除く)に適用されるのと同じファイルサイズの制限が適用されます。
Googlebot とは | Google 検索セントラル | Documentation | Google for Developers
HTML の場合、上から順にコードを読み込んでいって 2MB に達すると取得が停止します。

一般的なサイトが対応不要な理由
Google はファイル別に情報を読み取ってくれるのですから、極端な話、画像ファイル 2MB + HTML サイズ 100KB ならまったく問題ありません。
そして、HTML のサイズが 2MB を超えることはまずないと考えてよいでしょう。
たとえば当サイトで 15,000 文字ほどの長文記事は、HTML サイズが 168KB です。
HTML サイズは、コードの文字数で左右されます。各文字のサイズは、ざっくり以下のとおり。
- 半角英数字:1 ~ 2 バイト
- 全角日本語:3 ~ 4 バイト
つまり、すべて日本語で書かれたファイルであっても、2MB に達するには 50 万文字以上が必要です。
50 万文字というと一般的なビジネス書 4 冊分ほどで、その文量を Web サイトの 1 ページに収めるなんてことはまずありませんよね。
ですから、2MB 制限について気にする必要はまったくないのです。
2MB を超えてしまうのはどんなサイトか
気にする必要はないとは言え、以下の条件を満たせば HTML 単体で 2MB を超えてしまう可能性があります。
- CSS や JS のコードをすべて HTML に吐き出している
- 画像を Base64 エンコードしている
とくに画像のエンコードは、単体でもひっかかるかもしれません。
Base64 エンコードとは、「画像をテキストデータにしたもの」です。
たとえば、以下の画像は PNG 形式で 78KB の容量となっています。

これを Base64 エンコードすると、100KB を超えたテキストデータとなります(半角英数記号 8,000 字)。
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAc...(長いので省略)つまり、そのぶんだけ HTML サイズが増えるということですね。
もし 500KB の画像 4 枚を Base64 エンコードして埋め込んでいたら、Googlebot が途中までしか読み込めないファイルになってしまいます。
Base64 エンコードが使われている(使われていた)理由
Base64 エンコードは、昔(HTTP/1.1 時代)の高速化手段の 1 つでした。
当時は「リクエスト数を減らす」ことが重視されており、CSS や JS を連結し、画像もテキストデータとして HTML に埋め込むのが正義だったのです。
その古い手法を使ったまま放置されているサイト、または古い手法から未だにアップデートしていない運営者が制作したサイトは、HTML サイズが 2MB を超えているかもしれません。
 瀬尾
瀬尾今でも、ごく一部の小さな画像だけ Base64 エンコードすることはあります。
それか、ハッキングにより不正なコードを埋め込まれてしまった場合も 2MB を超える可能性があります。そうなると Googlebot の制限とは関係なく、スパムサイトとして検索順位に影響してしまいますが…。
自分のサイトをチェックして、もし 2MB を超えていたら、まずは高速化設定まわりを疑ってみてください。
まとめ
通常のサイトで HTML サイズが 2MB を超えることはまずありません。
古い高速化手法を使ったままだと影響する可能性があるので、そこだけご注意ください。
もし検索順位やアクセス数の大幅な低下が見られるなら、別のところに問題があると思います。
ブログのアクセス数が急に減ったのはなぜ?激減する理由と対策方法